7. How do we build a dataset with the business problem in mind?
Part 7 of the AI Product Management series of blogs


A business operator or product manager/owner has a lot of domain knowledge and know-how about the product and can identify the areas within the product that can be improved with machine learning. However, in order for machine learning models to work seamlessly, it requires relevant data.
Hence, the first step in building an AI product to solve the business problem involves building a good dataset to train the machine-learning models on.
What is the process of getting a good dataset?
When developing AI Products, the data used to train the model is far more important than the model itself.
The 3 steps in ensuring you have the right data for your model include:
Identify the data you need
Once you’ve clarified the Goldilocks problem you’re going to solve, it should be fairly straightforward to identify the data you need in order to solve it. The problem itself will dictate the qualities of the data you’ll need and your data science team can help with the finer details.
For our example of automation of customer service informational queries, we would need an exhaustive dataset of various examples of these queries.
b. Acquire the right data
Once you have identified the necessary data, the next step is acquiring it. Review any data you already possess for accuracy and annotation. Then, locate the source(s) from which you can acquire the rest of the data you'll need. Ensuring that you can secure a steady source of high-quality, annotated data for the duration of the model's existence is a fundamental prerequisite for the project's success. Without the right data, your project is likely to fail in multiple ways.
Depending on the problem you're trying to solve, you may be able to create the missing data. For example, if you're optimizing a purchase workflow on an e-commerce website, you can track user interactions and clicks with an application.
If you're starting from scratch, you can also partner with a data-sourcing company to meet your data needs. Sourcing the right data can be costly, but if you've selected a good Goldilocks problem, acquiring accurate data for a model to solve the problem will have the biggest business impact.
c. Continuously update the training data
Models must be trained continuously, or they will become less accurate over time due to changes in the real world (known as "model drift"). It is crucial to ensure that your data is updated on an ongoing basis.
For example, suppose you have a content moderation model. The language and slang used today are different from those used years ago when the models were first created. Without constantly re-annotating and retraining the models, they may allow more and more explicit content through as public opinions and standards change.
Therefore, it is important to refresh the model with new data to keep it up to date and enable it to handle the new reality. Your data is only as good as the point in time when it was collected.

Once you have built the training data set, check whether it answers the below two questions.
1. Data - Problem Fit / Does the data set represent the business problem?
The data should also represent the problem we are trying to solve. We can't train a model off of artificial data.
In order to achieve Data-Problem Fit:
Use real-world data to ensure the training data matches real-world scenarios. For example, use all types of machinery noises you would like to track in real-time in the model, to detect any anomalies in heavy mining machinery.
Determine the success criteria for the trained model
The success criteria for the model involve defining:
Precision
Recall
F1 Score
Precision, recall and F1 score are different metrics for measuring the "success" or performance of a trained model, which we will discuss in detail in a future post on training and evaluating a model.
If the model is not meeting the success criteria defined (and hence not able to meet the business outcomes), we need to go back and re-train the model. This could entail including more edge cases, more instances of data classes where the model performed poorly, or clearing up ambiguity among classes.
2. Data Completeness / Does the dataset contains enough information to represent all the real-world use cases?
Data needs to represent all the scenarios that could come up in real-world use cases.
Check whether the data you have collected helps with the problem you are trying to solve and ultimately benefits the end user.
Look for the relationships; patterns and similarities in the training dataset and identify potential anomalies or missing data. If there are any missing pieces, conduct more research and get the best data to serve your use case.
Once the dataset is checked for fit and completeness it is time to annotate the data.
Data Annotation
Data annotation helps machines make sense of text, video, image or audio data.
Data annotation is especially used for supervised learning, where the learning algorithm associates input with the corresponding output, and optimizes itself to reduce errors.
Data annotation comes down to labeling the area or region of interest—this type of annotation is found specifically in images and videos. On the other hand, annotating text data largely encompasses adding relevant information, such as metadata, and assigning them to a certain class.
The most commonly used types of data annotations include:
Image Annotations:
Image annotation helps machines understand the elements present within an image. This can be achieved by using Image Bounding Boxes (IBB), in which elements of an image are labeled with basic bounding boxes, or through more advanced object tagging.
Annotations in images can range from simple classifications, such as labeling specific objects in an image, to more complex details such as labeling the crop conditions, like whether the crop is looking healthy or unhealthy. These datasets are then used to build AI-enabled systems such as self-driving cars, cancer detection tools, or drones that assess crops and inspect farmlands
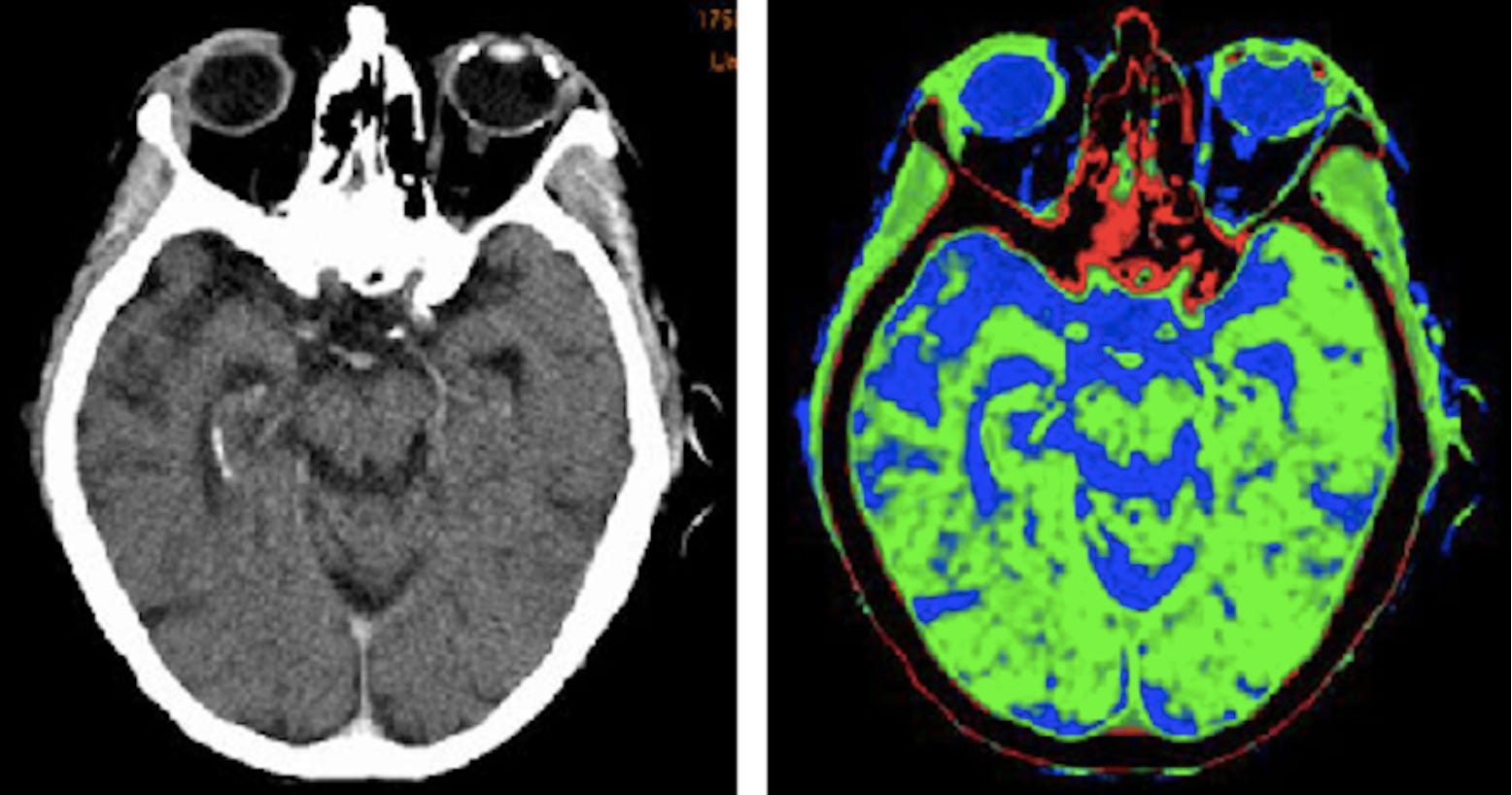
original CT scan (left), annotated CT scan (right) via semanticscholar
Video Annotation:
Video annotation works similarly to image annotation, where single elements within frames of a video are identified, classified, or even tracked across multiple frames using bounding boxes and other annotation methods. For example, it can tag all known animals in a zoo camera video as "Inhabitants" or help autonomous vehicles recognise objects along the road.
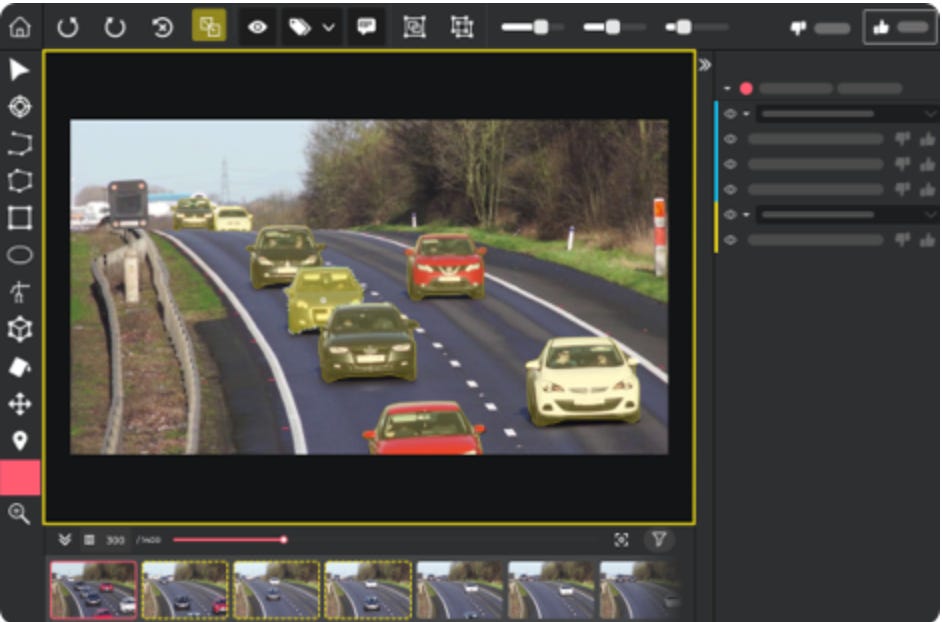
Source: SuperAnnotate
Text Annotation
There is an incredible amount of information within any given text dataset. Text annotation is used to segment the data in a way that helps machines recognize individual elements within it. The most common types of text annotation include:
Entity Tagging: Single and Multiple Entities: Named Entity Tagging (NET) and Named Entity Recognition (NER) help identify individual entities within blocks of text, such as “person,” “book,” or “city.”
This type of data annotation creates entity definitions so that machine learning algorithms will eventually be able to identify that “London” is a city, “Sia Kate Isobelle Furler” is a person, and “Colour the Small One” is an album.

People/band names are in orange, countries are in lighter orange, cities are in yellow, and album titles are in red. Source: Telus International
Sentiment Tagging: Humans use language in unique and varying ways to express thoughts and this is why sentiment tagging is crucial in helping machines decide if a selected text is positive, negative, or neutral.
Semantic Annotation: The meaning of words can vary greatly depending on the context and within specific domains. For example, the domain-specific language used in a business conversation in the consulting industry is very different from that used in the banking industry, or the slang used across two generations. Semantic annotation provides the extra context that machines need to truly understand the intent behind the text.
Adding Annotations via a Platform
There are many third-party data annotation platforms where you can upload annotation jobs.
The platform sends unlabeled data to human annotators, who will then classify or add features to the data and send it back in a tabular format. Cloud service providers like AWS offer data annotation services, as do specific companies
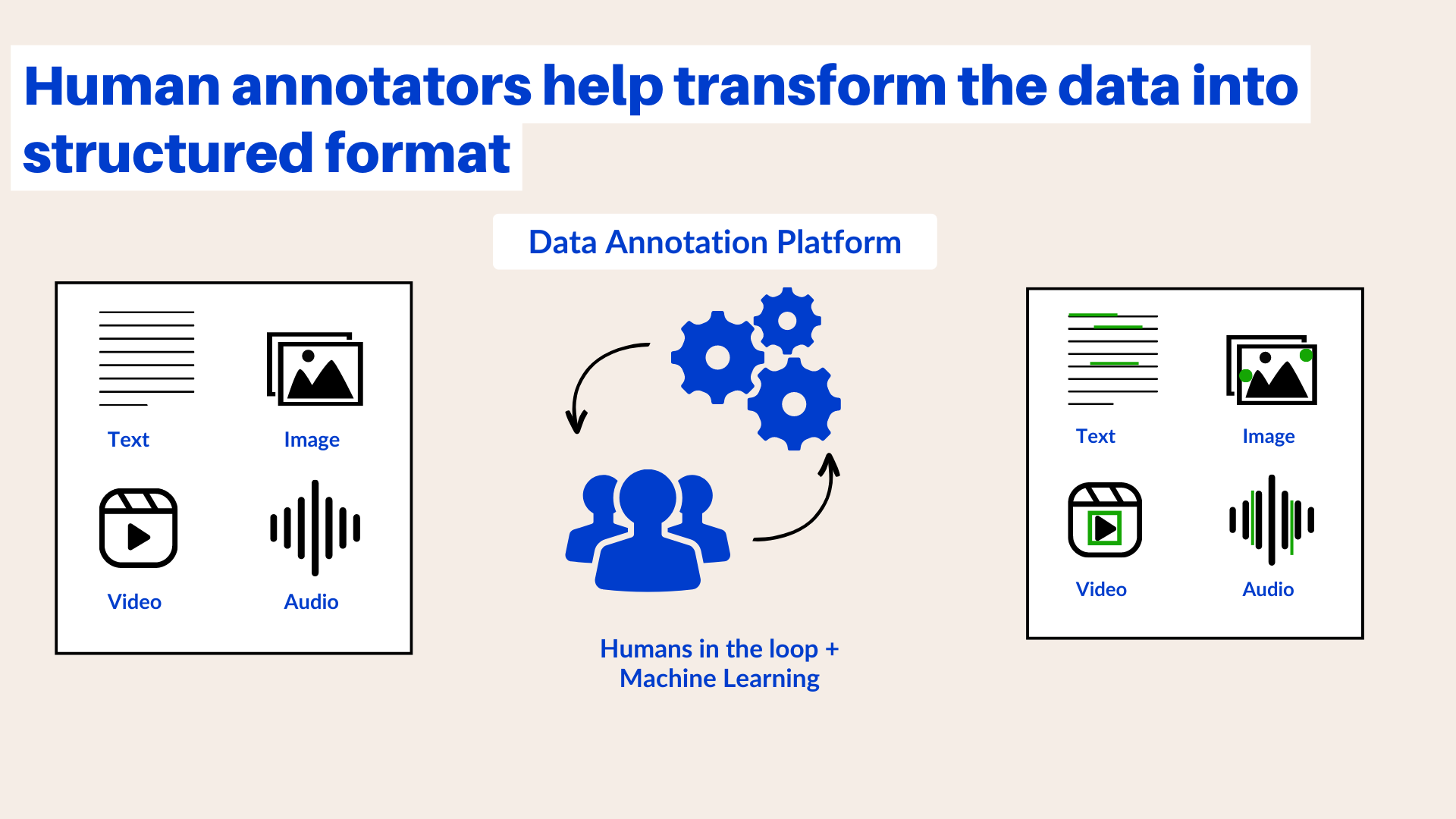
To use a data annotation platform, you can upload data and design an annotation job by providing a few samples of how the data should be annotated. This includes details on what to look out for and the labels to apply. You can also create a set of sample test questions with answers to help human annotators learn. Once the job is designed, launch the annotation process and monitor the results. If the results are not satisfactory, you can add more sample questions to clarify any ambiguous labels so that human annotators have clarity.
While creating an annotation job, please keep in mind that:
We need to design for the unknowns (Planning for failure):
How do you handle cases the model hasn't seen before?
Always design an option with the least negative impact so that model has a fallback option for data it hasn’t encountered before.
We need to plan for longevity (Planning for longevity):
If your data doesn't change, you can use a static model (no need for updates)
However, for frequently changing data, you may need to change the annotation job and update your data to include more relevant definitions or examples on a regular basis. For ex: if in future we have self-flying cars, we will need to include them while developing navigation apps.

Thanks for reading. In the next post, we will discuss the common data errors.