

Embeddings are one of the foundational concepts behind many modern AI applications, from search and recommendation engines to chatbots and generative models. But what exactly are embeddings, why are they so important, and how are they created? Let’s break it down.
What are Embeddings?
At their core, embeddings are numerical representations of data. They convert complex data (like words, sentences, images, or even videos) into numerical representations known as vectors. This transformation allows machines to process and analyse data efficiently.
For example, words in a language can be represented as vectors in a continuous vector space, where semantically similar words are positioned closely together.
For example, the words “cat” and “dog” may have vectors close to each other in the embedding space, while “cat” and “car” will be far apart, reflecting their real-world semantic similarity.

Why Are Embeddings Important?
Embeddings allow AI models to:
Semantic Understanding: By mapping entities (words, images, nodes in a graph, etc.) to vectors in a continuous space, embeddings capture semantic relationships and similarities, enabling models to understand and generalise better. For instance, the words “cat” and “dog” are related in a way that “king” and “cat” are not.
Computational Efficiency: By reducing the dimensionality of data, embeddings make computations faster and more efficient. High-dimensional data, such as text, images or graphs, are transformed into lower-dimensional representations, making it computationally efficient and easier to work with.
Generalisation: Embeddings help models generalise better by focusing on essential features and discarding noise. By learning meaningful representations from data, models can generalise well to unseen examples, making embeddings crucial for tasks with limited labelled data.
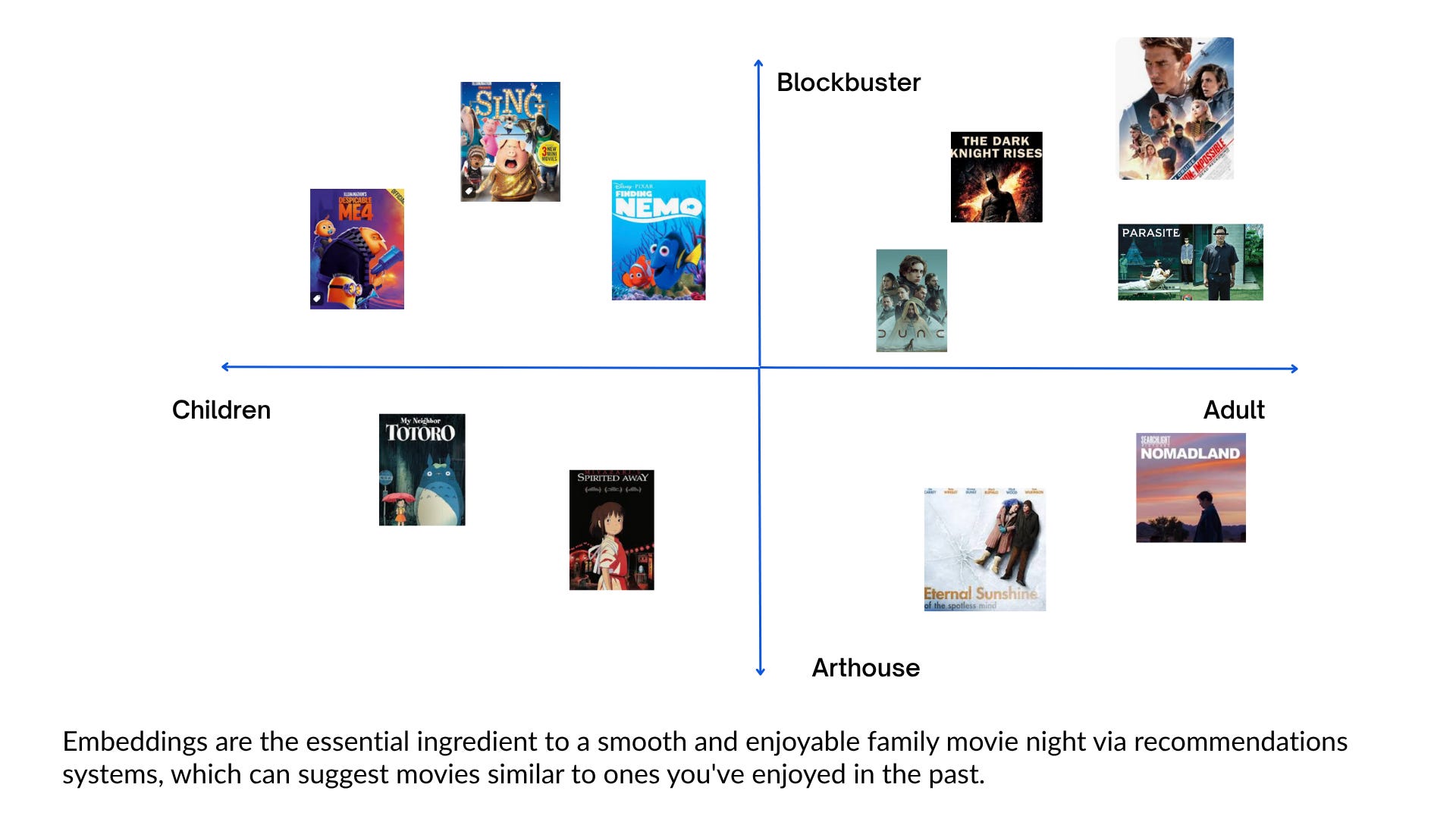
Power key tasks: Embeddings facilitate efficient and accurate similarity searches, hence tasks like Search, classification, clustering, retrieval, and recommendations are all made smarter with embeddings.
What Can Be Embedded?
Almost any kind of data can be “embedded”:
Words: Word embeddings capture the semantic relationships and contextual meanings of words based on their usage patterns in a given language corpus. Each word is represented as a fixed-sized dense vector of real numbers.
Text: Text embedding extends word embedding to represent entire sentences, paragraphs or documents in a continuous vector space. Text embeddings play a crucial role in various NLP applications, such as sentiment analysis, text classification, machine translation, question answering and information retrieval.
Images: Image embedding is designed to capture visual features (Colour, shape, etc.) and semantic information about the content of images. Image embeddings are particularly useful for various computer vision tasks, enabling the modelling of image similarities, image classification, object detection and other visual recognition tasks.
Audio: Audio embeddings capture the relevant features and characteristics of audio data (timbre, genre, etc.), allowing for effective analysis, processing and similarity metrics. Audio embeddings are particularly useful in applications such as speech recognition, audio classification and music analysis, among others.
Video: Sequential frames and sound are embedded to characterise actions or events, combining image and audio features.
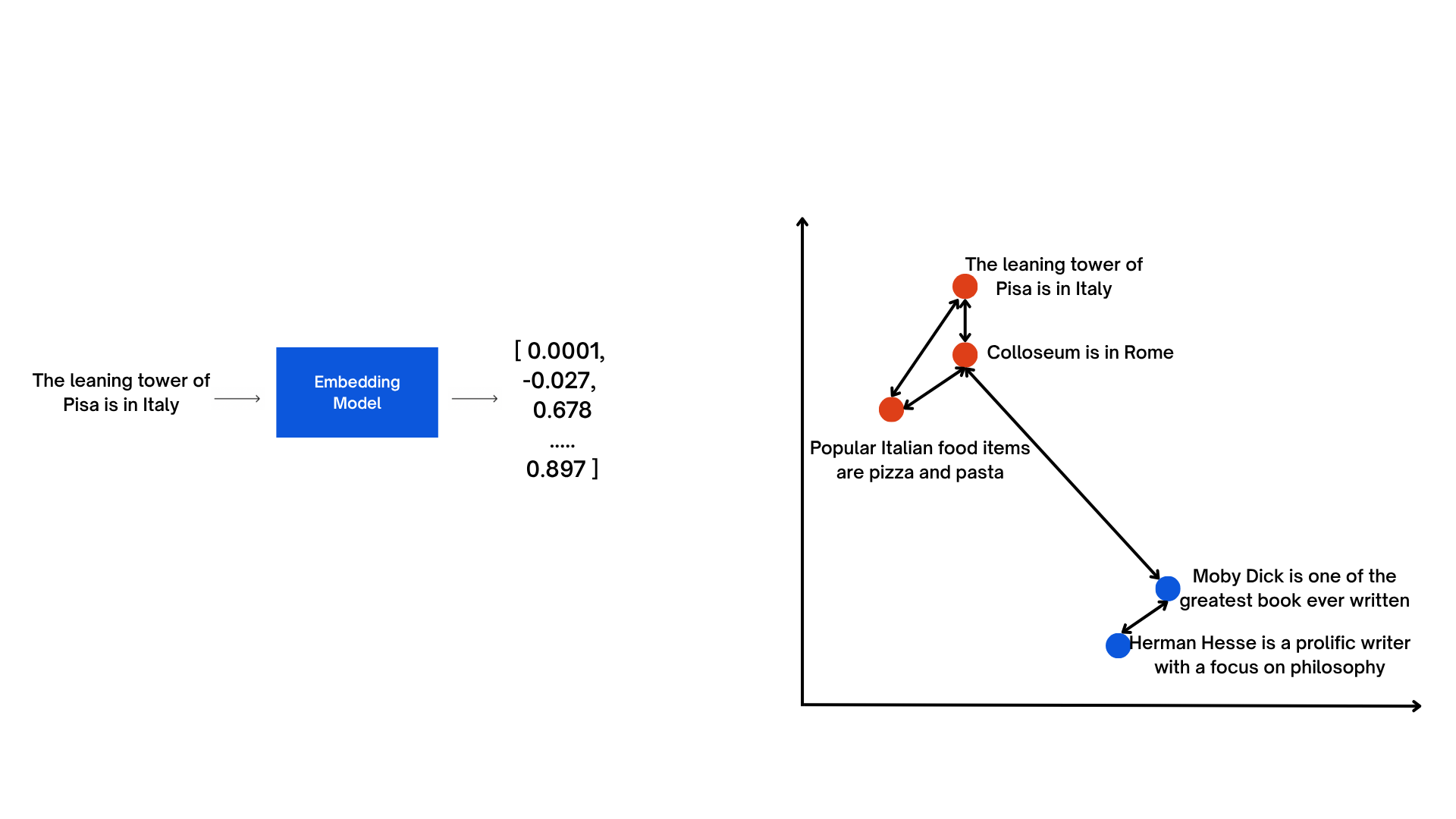
How Embeddings Are Created?
Typically, embeddings are generated by training machine learning models—often neural networks—that learn the “best” way to represent data as vectors. There are several pre-trained models you can choose from.
Embeddings are created following these general steps:
Choose or train an embedding model: Select a pre-existing embedding model suitable for your data and task, or train a new one if necessary. For text, you might choose Word2Vec, GloVe, or BERT. For images, you might use pre-trained CNNs like VGG or ResNet.
Prepare your data: Format your data in a way that is compatible with the chosen embedding model. For text, this involves tokenization and possibly preprocessing. For images, you may need to resize and normalise the images.
Load or train the embedding model: If using a pre-trained model, load the weights and architecture. If training a new model, provide your prepared training data to the algorithm.
Generate embeddings: For each data point, use the trained or loaded model to generate embeddings. For example, if using a word embedding model, input a word to get its corresponding vector.
Integrate embeddings into your application: Use the generated embeddings as features in your machine learning model, or for similarity search, recommendation, clustering, etc., depending on your specific task.
In all embedding cases, the idea is to represent data in a continuous vector space where meaningful relationships are preserved. The training process involves adjusting the parameters of the model to minimise the difference between predicted and actual values based on the chosen objective function. Once trained, the embeddings can be used for various downstream tasks.
For example, if you have recently used a video streaming service which recommended movies to you, you have come across an algorithm which uses embeddings.
What Are Embedding Models?
Embedding models are specialised neural networks designed to convert raw input (words, sentences, images, etc.) into vectors. Most common ones include:
Word2Vec, GloVe: Early models for word embeddings.
BERT, GPT, RoBERTa: Modern models can embed entire sentences or documents.
CLIP, DINO, OpenCLIP: Popular multimodal models for image and text embeddings.
Choosing the right model depends on the type of data (text, image, audio) and the application.
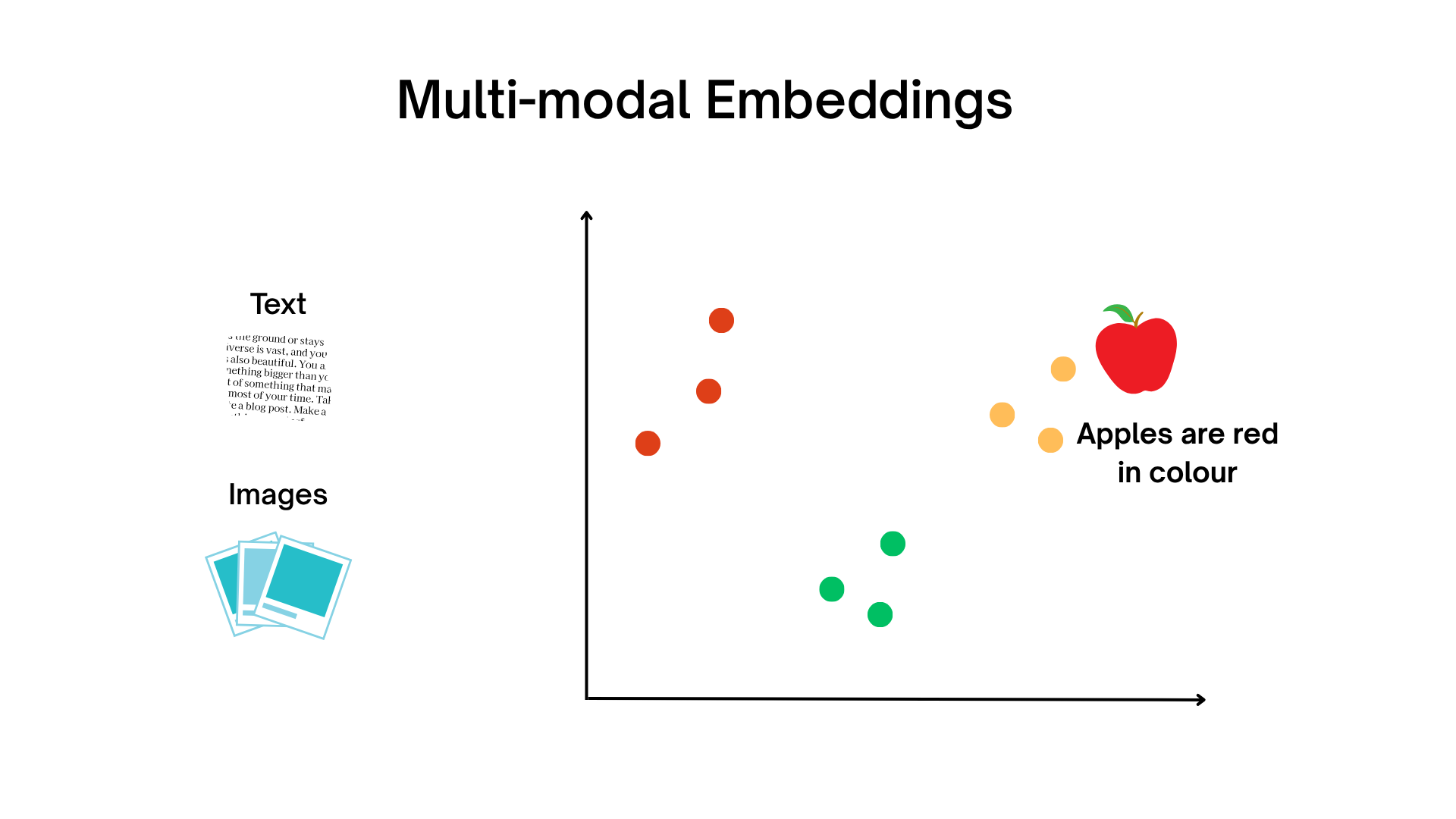
What Are Multimodal Embeddings?
Multimodal embeddings combine information from different data types, such as text and images, into a shared vector space. This method lets AI systems understand connections between words, pictures, sounds, and more.
A standout example is OpenAI’s CLIP, which embeds both text and images so you can search for images using natural language or describe an image in words—and get matching vectors. Multimodal embeddings unlock richer, more flexible search, recommendation, and understanding capabilities in AI.
Quick Review
Embeddings turn complex data into useful vectors.
They’re essential for making AI understand, compare, and search across varied information types.
Embedding models are the backbone of multimodal approaches are pushing AI toward deeper, cross-format understanding.