10. Human in the Loop (HITL) Machine Learning
Part 10 of AI Product Management series of blogs


We have heard in the news of Microsoft’s Twitter chatbot turning racist, Tesla on autopilot killing 2 people or Amazon’s internal AI recruiting tool that was biased against women. We ourselves may be wondering whether our Generative AI models would spew out some undesirable content when deployed?
When we are building complex machine learning models, are there ways in which we can reduce these incidences and make use of human intelligence to augment the desired outcomes of our models? Human-in-the-loop (HITL) may be the best answer available to us.
What is Human in the Loop (HITL) Machine Learning?
Human in the loop (HITL) is a process of continuous learning wherein humans can help the ML model when it encounters data that is new to it and has to make a prediction in which the model has very little confidence.
AI systems excel at learning to make optimal decisions when given large, high-quality datasets. However, in the real world, such datasets are rare, which often limits the capabilities of machine learning. On the other hand, human intelligence is adept at recognizing patterns within small and poor-quality datasets. By combining these different skillsets in a feedback loop, HITL machine learning enhances machine learning capabilities.
Human-in-the-loop can refer to different people and be used in different contexts. Typically, the "humans" involved are specialists who help reduce the number of errors and supervise the learning process of machines. These experts can come from a variety of roles, including data annotators, support teams, quality assurance personnel, data scientists, and machine learning engineers.
In short, HITL machine learning refers to a set of strategies that combine human and machine intelligence in AI applications. The goals of these strategies typically include:
Increasing the accuracy of machine learning models
Decreasing the time to achieve the target accuracy for an ML model
Increase the operational efficiency of AI/ML models
"Can we use more data or better algorithms to achieve higher confidence?”
The field of Machine Learning has witnessed remarkable technological advancements in recent years. Nonetheless, it appears that nothing can beat a simple equation:
more training data = better performance
However, obtaining training data that is clean, representative of the real world and unbiased is always a challenge, and it requires human expertise. While many public datasets are available, they typically do not pertain to your specific problems and must be created.
To avoid spending years constructing a dataset, you can begin training a model with HITL and start using it sooner. In many cases, this approach results in significant productivity gains too.
The HITL machine learning process
HITL machine learning process is typically used in two broad stages; training and testing.
Preparation of Training data a.k.a Labelling/Annotation
While prepping the data for training an ML Model, humans label both the input and corresponding expected output training data.
In supervised machine learning, this process provides the algorithm with accurately labeled data so that it can make future predictions efficiently.
In unsupervised machine learning, with unlabelled datasets, the algorithm is designed to seek and define its own structure of the unlabelled data. Then a human can look at the classes created by the algorithm and make any changes as required. This falls under the HITL deep learning approach.
Testing and evaluation
In both supervised and unsupervised HITL machine learning, the purpose of testing and evaluation is to allow humans to correct any inaccurate results the algorithm produces when presented with new data.
There are broadly two categories of inaccurate decisions:
The algorithm has low confidence in accuracy (edge cases), and
The algorithm is confident, but the result is incorrect.
Active learning is a process in which feedback from humans is provided to machines for interpreted low-confidence results. The purpose of testing and evaluation is to enable the algorithm to improve decision-making such that it ultimately does not rely on human intervention.
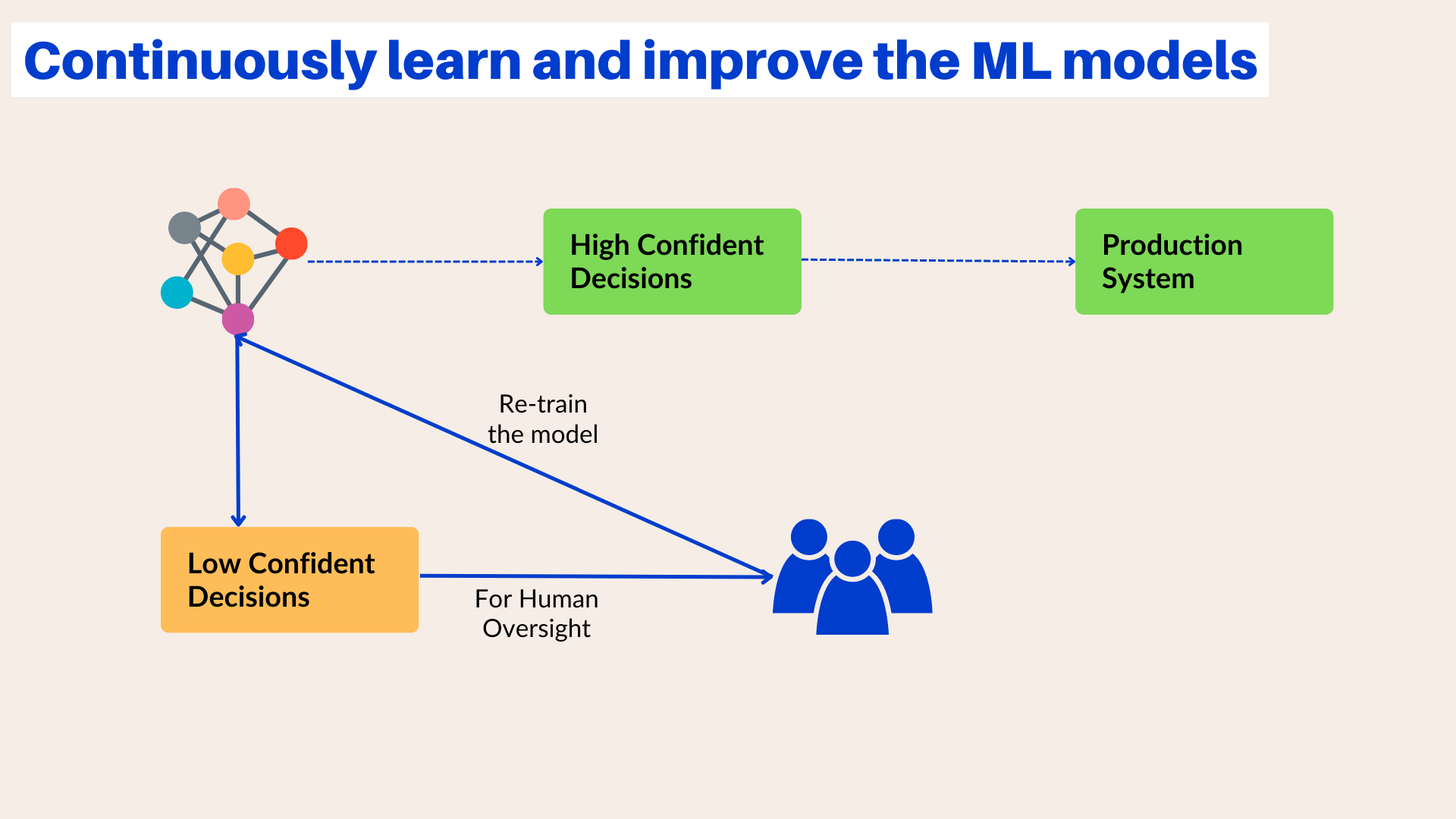
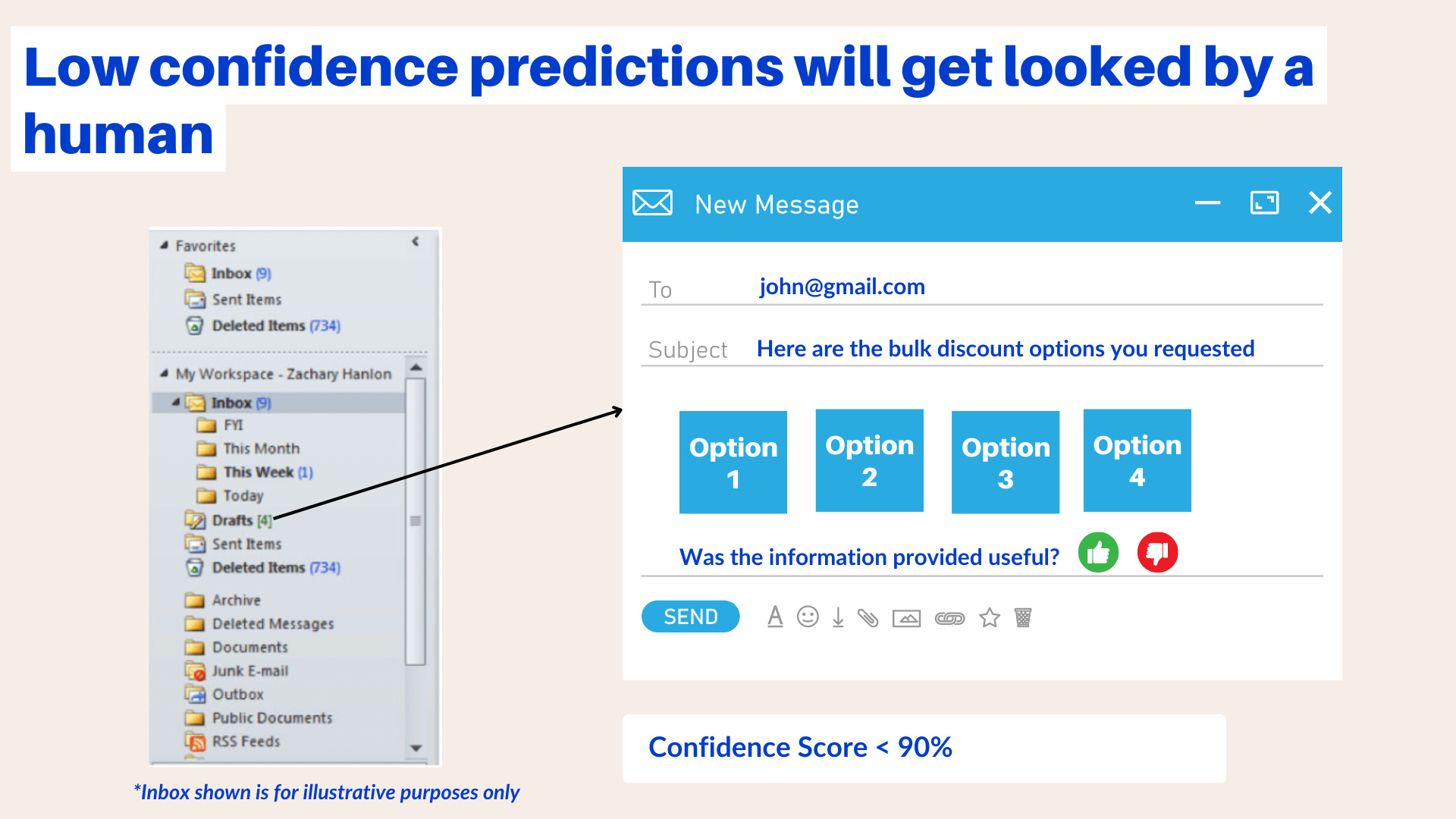
An example of this is illustrated in the informational query auto-responder we started building in our previous post. Our ultimate goal is for our ML model to categorize and answer all queries related to bulk discounts and international shipping. However, when we initially test and deploy our automation in production, it's possible for our model to encounter scenarios where it's not completely confident in its prediction. For instance, if we're working with a confidence score of 90%, and the model predicts an outcome with a confidence score of 80%, we can ensure that a human reviews it before releasing it. We can store the auto-response email to the customer in a draft folder, and a human can check it before hitting send, to avoid false positives.
Consolidating the processes of training, testing, and evaluation creates a continuous feedback loop between humans and the ML model. This loop improves the accuracy and consistency of the algorithm by refining and expanding the scope of edge cases.
As time passes, the ML model will be even capable of analyzing its own performance and identifying areas where it is less effective. The data is then sent to humans, which improves the efficiency of feedback and the overall human-in-the-loop (HITL) machine learning process.
Human-in-the-Loop Benefits: Why Do People Matter?
Increasing Quality
Accounting firms have been using AI to keep up with the demands of having to manually re-examine thousands of documents for clients to comply with every new regulation. They consistently use human-in-the-loop (and NLP entity extraction) to validate the results to make sure their AI system is consistent and efficient.
Leveraging Domain Expertise
To build a competitive machine learning algorithm, incorporating unique knowledge from domain experts is crucial. The Nasdaq discovery tool, which aimed to improve trading activities management, was built with the help of human analysts. This human-in-the-loop approach also covers corner cases, such as rare or insufficient data, and can serve as a barrier to training ML models without human supervision. Facebook still relies on human experts to monitor social activity, as it's difficult to teach all the nuances of communication to an AI system.

Increasing Accuracy / Lowering the Number of Errors
Introducing machine learning into a workflow can greatly benefit automation. The combination of ML and human effort can produce the best results through "human-in-the-loop" automation. A prime example of this approach is the use of Google Deepmind for breast cancer detection. The combined system with doctors resulted in a reduction of false negatives, demonstrating how machines can facilitate the work of human experts to enhance overall accuracy and lower the number of errors.
Human-in-the-Loop Disadvantages: We are unique beings :)
Expensive
Labelling requires people to annotate and categorise image, text, audio, or other files. This process can be done in-house or outsourced, but either way, it represents a significant cost. Additionally, providing continuous human feedback during the training and evaluation phase also adds to the overall expense.
Time-consuming
The Human-in-the-Loop (HITL) process is a manual process that requires significant time and effort. It can take several weeks or even months to complete data annotation jobs. Further monitoring of the testing and evaluation of models until they reach the required accuracy is a mammoth undertaking in itself.
Use smart selection to your advantage in HITL Machine Learning
One way to mitigate the disadvantages of HITL is through smart selection. To optimize performance without incurring high costs, it's important to recognise and let humans handle only the data and scenarios that will have the greatest impact on the model.
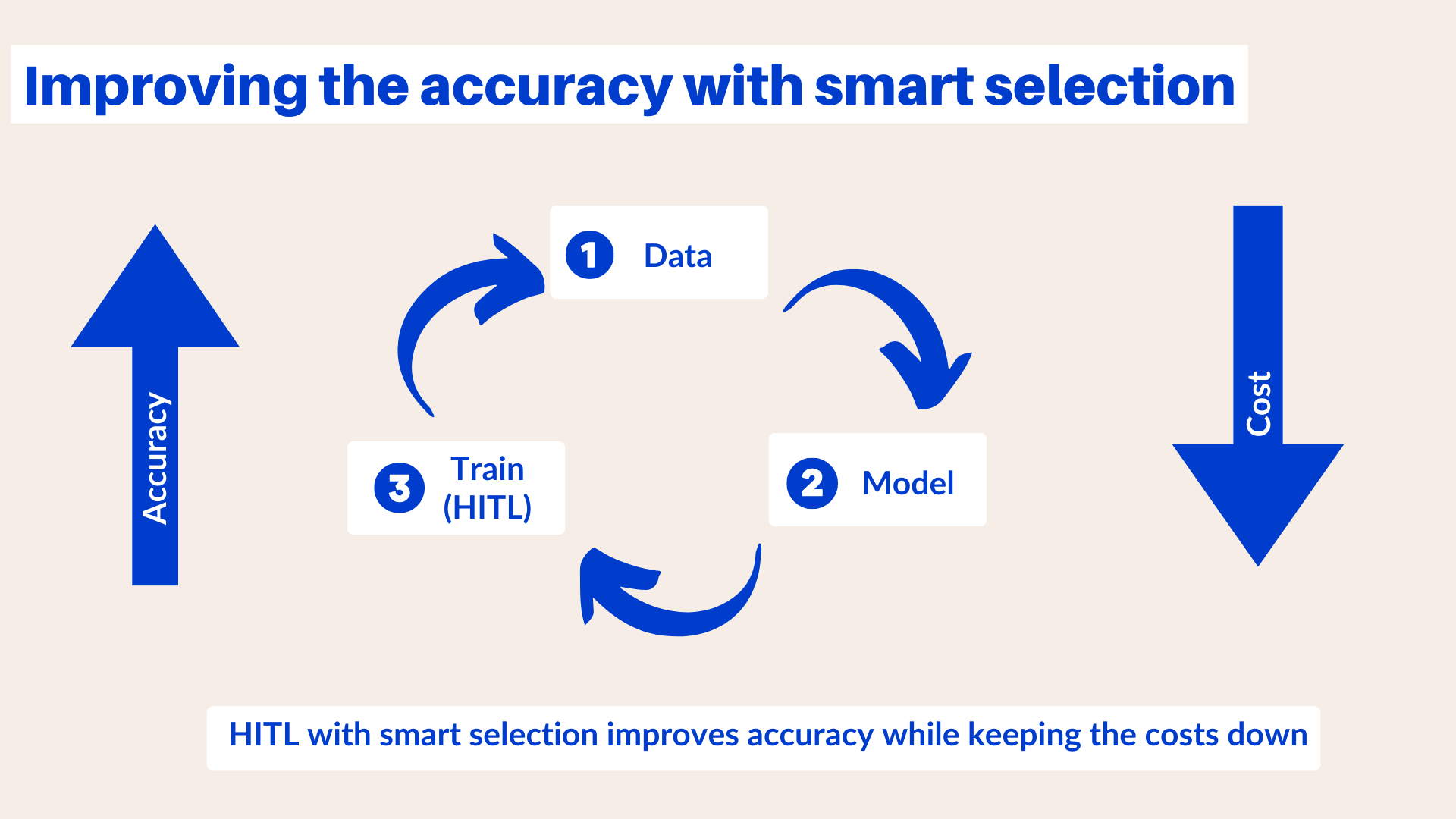
One way to achieve this is through smart selection methods. Instead of processing all unlabeled data, choose the most relevant data that can improve accuracy and discard any data that could potentially harm the model and reduce accuracy. This approach leads to improved model accuracy while concurrently reducing costs.
How does smart selection work?
With smart selection, you can identify the most valuable training data units for human annotation. This data analysis can really maximize the accuracy gain of your model.
Smart selection accounts for four different criteria:
Low-Confidence - any data or scenario that the model has low confidence in.
Uncertainty - scenarios that the model is unable to predict.
Novelty - any new data that comes up and the model has never been trained on.
Class importance - Identify the classes of data that are important for your model and the data related to those classes are given higher priority, with re-training of the model with those types of datasets.

Human in the loop with smart selection helps us improve the accuracy of our models without increasing the cost very much. Have you ever used HITL Machine Learning in your work?
Thanks for reading. See you in the next post.