2. Machine Learning Concepts & Basic Algorithms / AI Product Management
Part 2 of the AI Product Management series of blogs

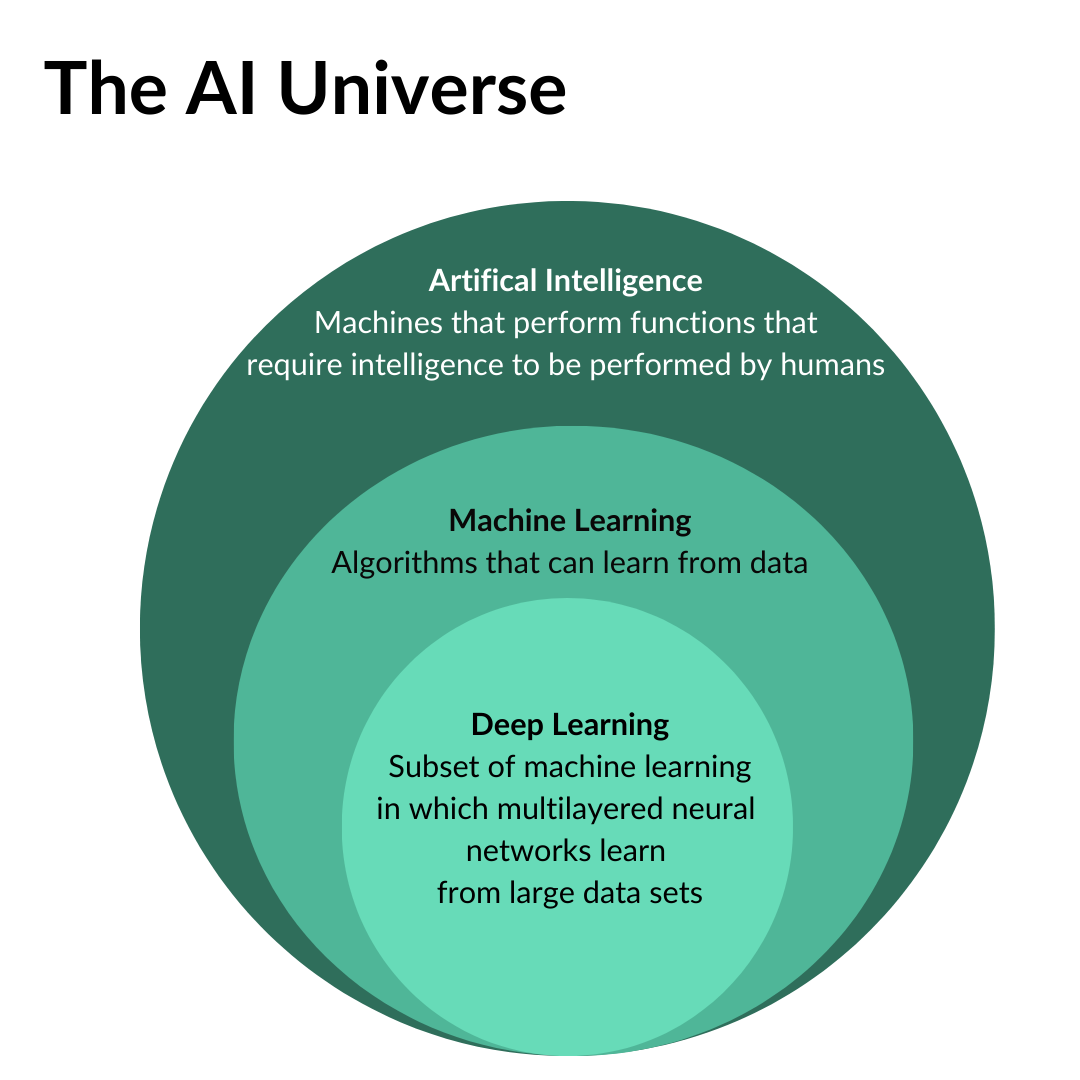
Machine learning refers to algorithms which can learn from data. Today, it often references supervised learning techniques where humans actually massage the data, design different representations or features of that data and train a model.
Deep learning is a subset of machine learning in which there are multilayered neural networks that learn from very large sets of data to predict outcomes from unstructured inputs.
Artificial Intelligence (AI) integrates perception (understanding the world); predicting, reasoning, and decision-making around getting to a particular outcome.
Machine Learning Techniques:
Machine learning is the study of computer algorithms that allow computer programs to automatically improve through experience.
-Tom Mitchell, Professor at CMU
Machine Learning Techniques can be broadly divided into:
Supervised Learning
Classification
Regression
Unsupervised Learning
Clustering
Association
Reinforcement Learning
Real-time
Offline
Supervised learning uses pre-labelled data to train a model to predict new outcomes for information that hasn’t been exposed before.
Unsupervised learning uses non-labelled data and self-organises to predict patterns or outcomes such as clustering or associations.
Reinforcement learning is giving feedback to an algorithm when it does something right or wrong based on a discrete outcome, this can either be in real-time or offline.
1. Supervised learning:
In its simplest form, supervised learning algorithms map an input to an output. It uses labelled datasets to train algorithms to classify data or predict outcomes accurately.
There are two main types of supervised learning algorithms:
Classification Algorithms
Classification Algorithms categorise unstructured data into particular categories or a class. For example, a classification algorithm can specify whether an image depicts a cat or not.

Regression Algorithms
Regression Algorithms identify the relationship between a dependent variable and one or more independent variables and is typically leveraged to make predictions about future outcomes. For example, how much would a house value given a number of parameters like address, square footage, number of bedrooms and bathrooms, availability of a pool/carpark, etc.
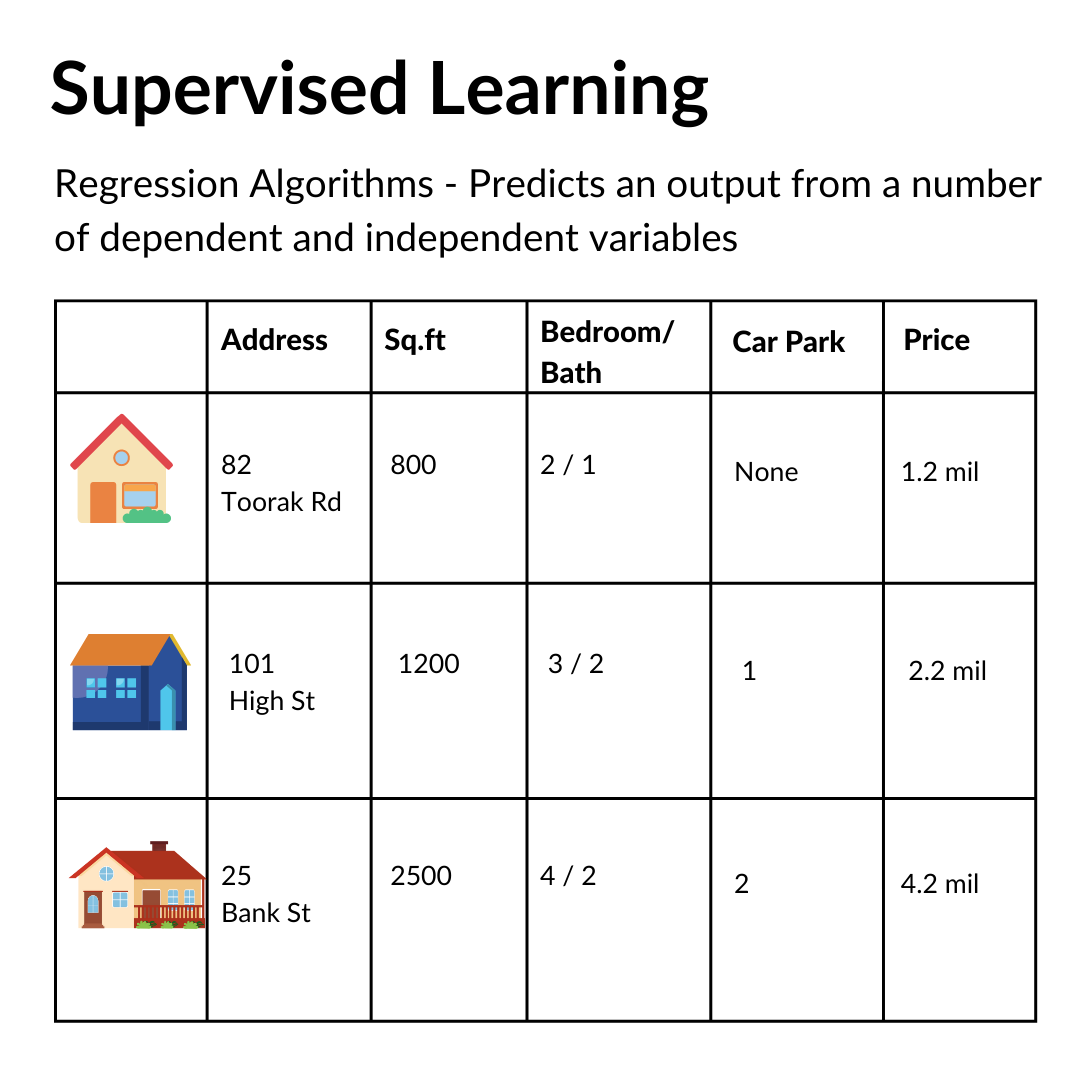
**This may or may not be an accurate representation of the Melbourne housing market :/
The main difference between classification and regression is that the output variable in a regression is numerical or continuous, while in classification it is discrete or categorical.
Some of the common supervised learning use cases include:
Image and object recognition
Spam detection
Sentiment Analysis
Facial Recognition
Audio transcription
Optical character recognition
2. Unsupervised learning
Unsupervised learning algorithms find patterns in data. Unlike supervised learning, unsupervised learning uses unlabeled data. These algorithms discover hidden patterns in data without the need for human intervention (hence, they are “unsupervised”). This is particularly useful when subject matter experts are unsure of common properties within a data set.
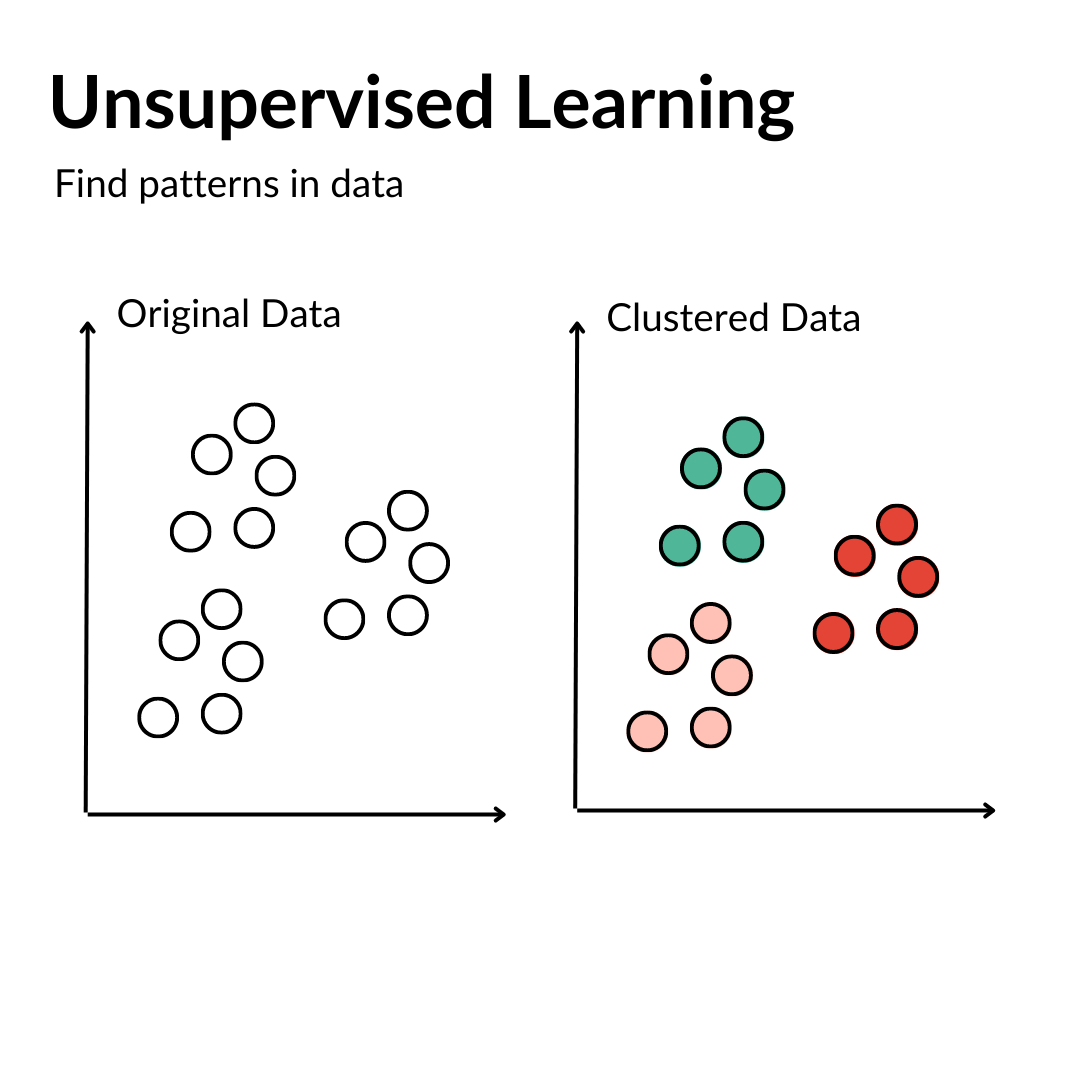
Unsupervised learning models are used for three main tasks: clustering, association and dimensionality reduction:
Clustering is a data mining technique for grouping unlabeled data based on their similarities or differences. This technique is helpful for market segmentation, image compression, etc.
Association is another type of unsupervised learning method used to find relationships between variables in a given dataset. These methods are frequently used for recommendation engines, along the lines of “Customers Who Bought This Item Also Bought”, recommendations.
Dimensionality reduction is a learning technique used when the number of features in a data set is too high. It reduces the number of data inputs to a manageable size while preserving the data's integrity. Often, this technique is used in the preprocessing data stage, such as when autoencoders remove noise from visual data to improve picture quality.
Some of the common use cases of unsupervised learning include:
Customer Segmentation: Group different customer segments to find common characteristics/behavior among groups with similar income levels, age, etc.
User Journey Segmentation: You can cluster customer journey into paths leading to the purchase decisions in an e-commerce website.
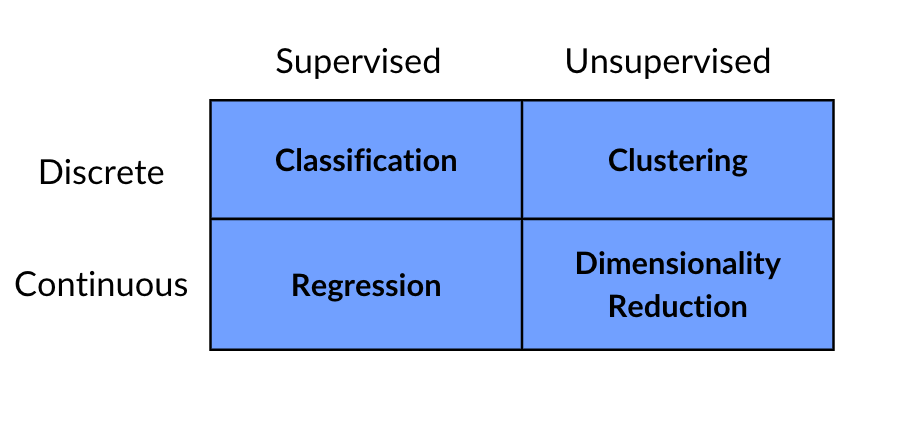
Supervised vs Unsupervised Learning
Below is a useful matrix that addresses all kinds of data analysis cases.
Discrete data is data you can count and has a finite amount, say the number of image classes or clothing item types.
Continuous data is often numerical data that takes a large range of values.
3. Reinforcement Learning
Reinforcement learning mimics how humans learn. Reinforcement learning broadly seeks inspiration from these human abilities to learn how to act.
For example, we show a picture of a giraffe to a child and say “Hey look, this is a giraffe”. Now the said child visits a zoo after a week and points to a giraffe and says “Hey look Nora, it is a giraffe” and when we say “Yes of course honey, it is a giraffe”, we are reinforcing the learning.
Reinforcement learning seeks to acquire the best strategy for taking repeated sequential decisions across time in a dynamic system under uncertainty. It explores how intelligent agents ought to take actions in an environment in order to maximize the notion of cumulative reward.
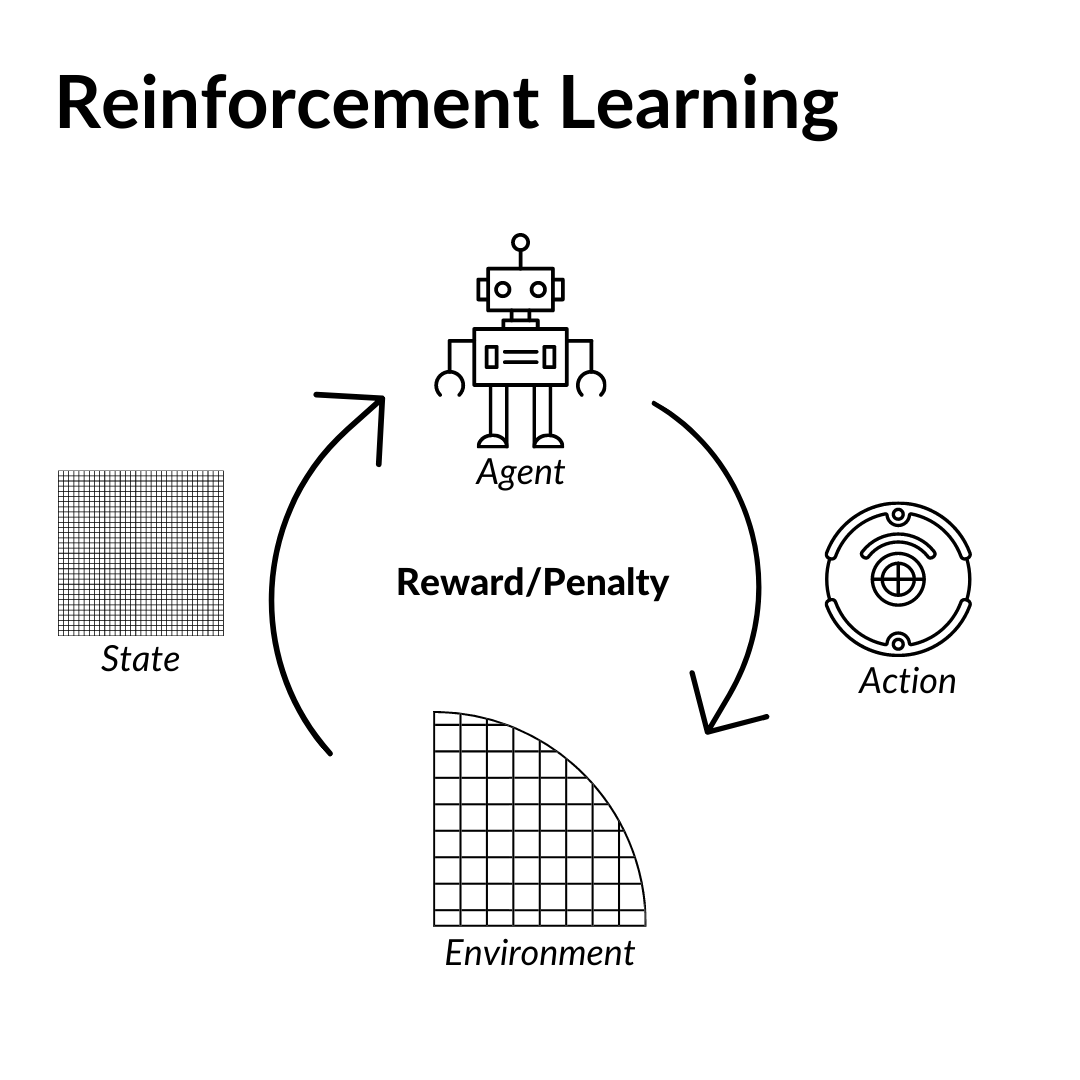
When you deploy reinforcement learning in production, it is best to have a human moderator who can reinforce the desired behavior of the model, to produce the most accurate results. Human in the Loop (HITL) refers to having a human-moderator or data annotator that can help to control the quality of a product.
If you don’t have human in loop in reinforcement learning to deploy in production, it can lead to unfavourable results. One of the prime examples of this is Microsoft’s “Tay” Twitter bot which posted inflammatory and offensive tweets through its Twitter account, causing Microsoft to shut down the service only 16 hours after its launch.
Two more terms that are useful to understand with respect to deep learning are:
Neural Networks:
A neural network is a deep learning technique that uses interconnected nodes or neurons in a layered structure that resembles the human brain. It creates an adaptive system that computers use to learn from their mistakes and improve continuously. Thus, artificial neural networks attempt to solve complicated problems, like summarizing documents or recognizing faces, with greater accuracy.
Neural network makes decisions based on weighing evidence. Inputs are yes-no questions, outputs are yes-no questions. Adding weights can influence the inputs and a threshold can help determine the output.
For example, you are trying to figure out whether you should go for a run now?
There are several factors which can go into this decision, like,
Are you free from doing anything else at the moment?
Is your running gear ready?
If I go now, can I run with a friend?
and whether the weather pleasant for a run now?
All these are relevant information for you to make a decision on whether you should go for a run now.
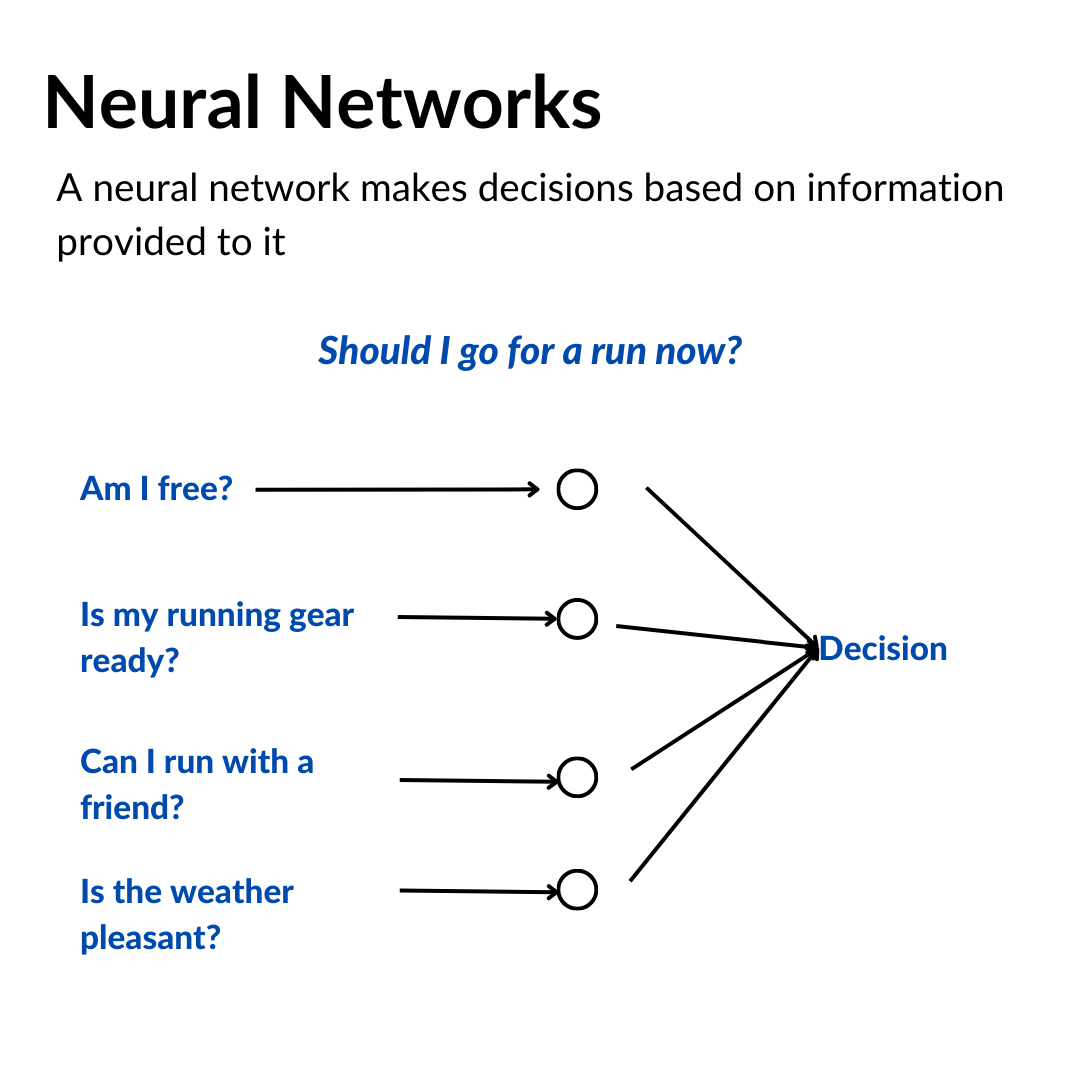
It can also happen that there is weight associated with each of these information points. For example, what if you value your running gear being ready is more important to you than anything else? These weights can influence the final decision and if we fix a threshold for making this decision, it can help us determine which combination of factors can lead to the decision.

As a good product manager, it is imperative that your team/data science team is aware of all of the data that’s critical for making this decision.
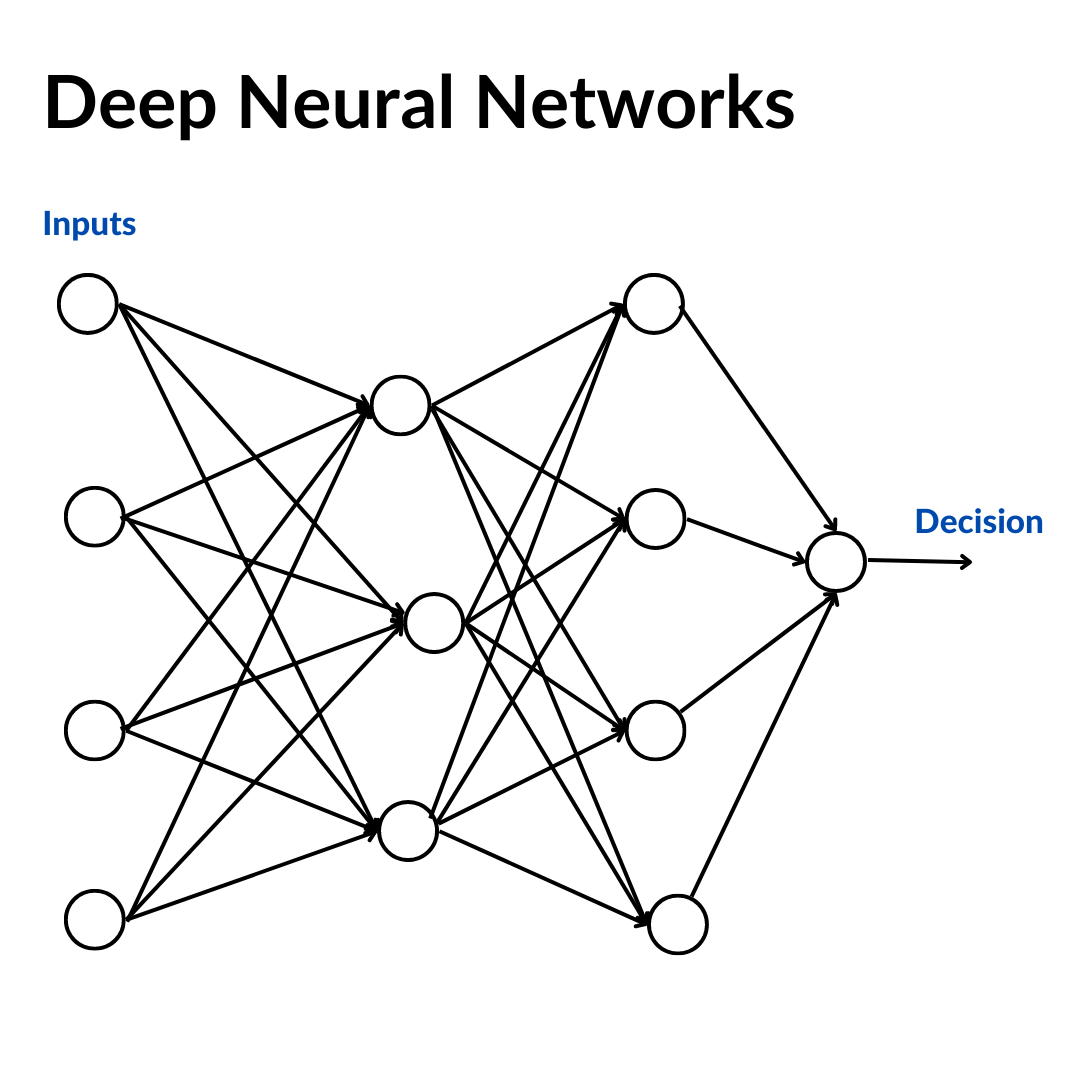
Deep Neural Networks
A deep neural network is an artificial neural network with multiple layers between the input and output layers. There can be dozens, hundreds or thousands of layers between inputs and output. Eg: Optical Character Recognition
In this post, we talked about a number of common concepts of Machine Learning/AI which product managers/business operators need to know. Considering the length of this post already, we will discuss further topics like Generative Adversarial Networks (GANs) and other algorithms in a separate post.
Next up: Why is it important to start with the business goal/customer problem while working on an AI project?